Using RAG (Retrieval Augmented Generation) to Achieve Lossless Data Compression
📚 Resources
Full technical details and methodology
Visual walkthrough of the concepts
RAG-enhanced compression system
GitHub repository with implementation details
I am also publishing paper in upcoming ACM conference
The Big Picture
Imagine you have a massive library of books, and you need to ship them all to another location. The traditional approach? Pack them as tightly as possible. But what if instead of just packing, you could understand the content and use that knowledge to pack even smarter?
That's exactly what we're doing with data compression, but instead of books, we're working with the billions of gigabytes created every day. By 2023, over 120 zettabytes of data were generated annually—that's like storing every movie ever made millions of times over. Efficient compression saves storage space, reduces costs, and speeds up data transfer.
The Problem with Current Solutions
Traditional compression tools like ZIP, gzip, and LZMA use algorithms like Huffman coding,arithmetic coding, and Lempel-Ziv methods. These work by finding patterns and replacing repeated sequences with shorter codes. While efficient for specific data distributions, they lack adaptability and fail to exploit higher-level semantic patterns.
Example: The string "AAABBBCCC" can be compressed to "3A3B3C" (run-length encoding)
Traditional methods are rule-based but don't understand context or meaning.
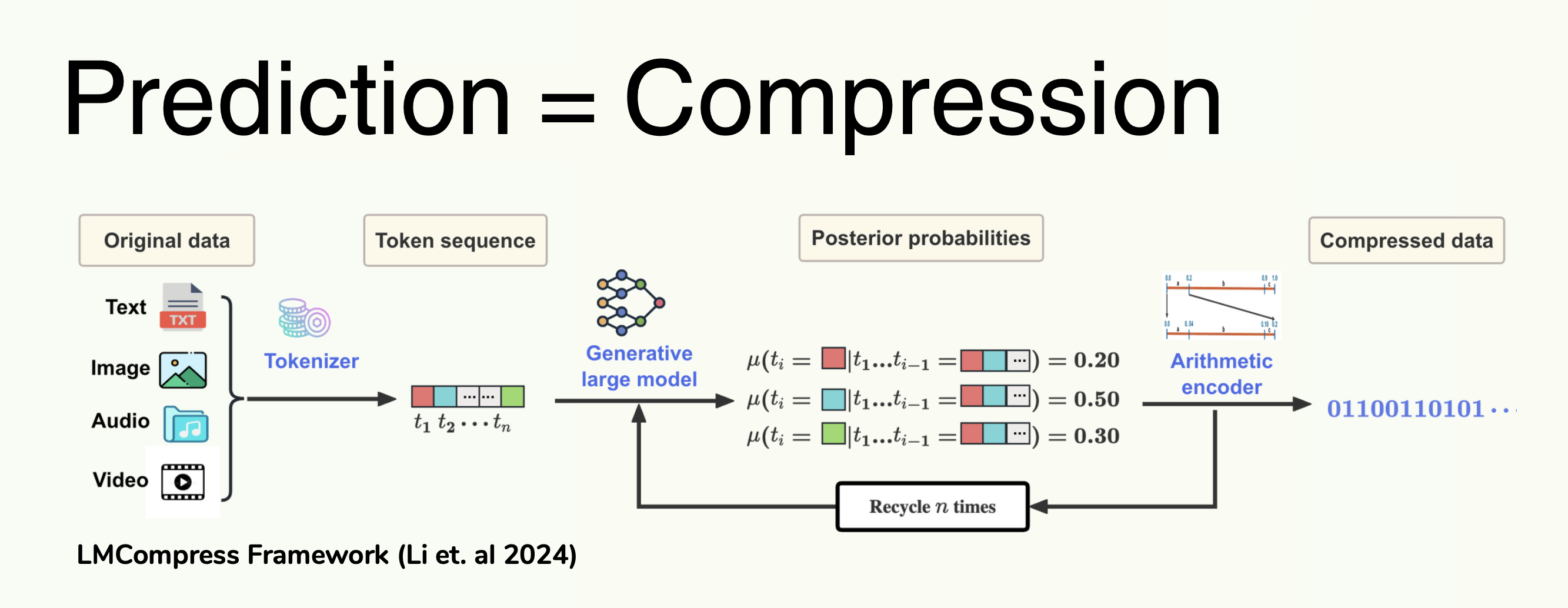
Recently, researchers discovered that AI language models (LLMs)—the same technology behind ChatGPT—can compress data by predicting what comes next. The fundamental insight comes from information theory: if we can accurately predict the next token with probability P(t), we only need -log2(P(t)) bits to encode it using arithmetic coding.
Shannon's Source Coding Theorem:
Expected bits = -∑j P(tj) × log2(P(tj))
Better predictions → Higher P(t) → Fewer bits needed → Better compression
But here's the catch: LLMs have a finite context window (typically 2048-4096 tokens). They can only look at recent data to make predictions, like trying to predict a movie's ending when you've only watched the last 10 minutes. This limitation leads to suboptimal compression for long-form or complex data.
Our Innovation: RAG-Enhanced Compression
We're solving this problem using Retrieval-Augmented Generation (RAG). The core idea: instead of relying solely on the LLM's limited context window, we give it access to a searchable knowledge base of relevant documents.
Mathematical Formulation:
Given a document D to compress, we first compute its embedding:
eD = fembed(D)
Then retrieve top-K similar documents from knowledge base KB:
Retrieved(D) = Top-K( { ej | ej ∈ KB, cos(eD, ej) } )
where cos(·,·) is cosine similarity in embedding space
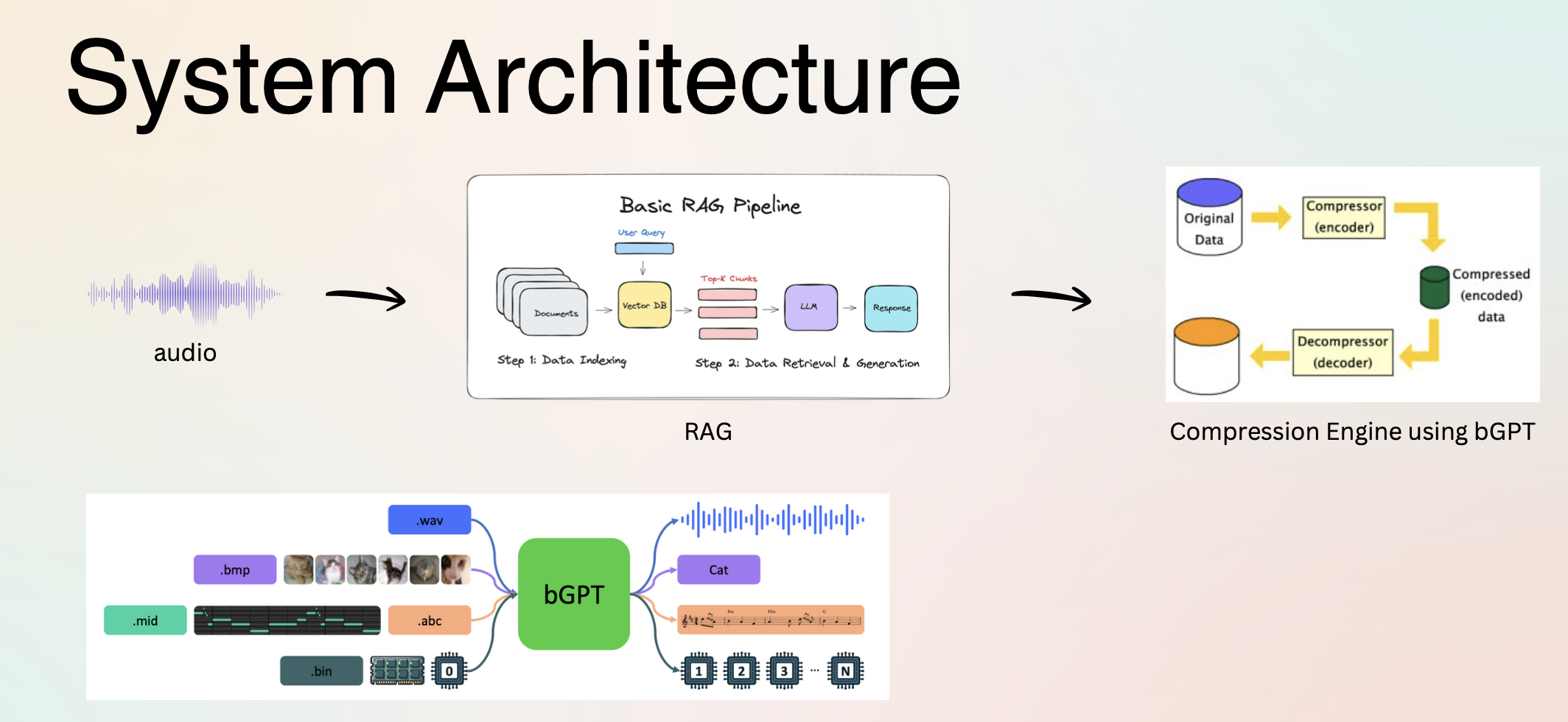
Here's how the system works step-by-step:
- 1.Build Knowledge Base: We embed ~1000-5000 Wikipedia documents using Qwen3-Embedding-0.6B model, converting each document into a 512-dimensional vector. These vectors are indexed in FAISS (Facebook AI Similarity Search) for efficient retrieval.
- 2.Semantic Retrieval: For each document to compress, we compute its embedding and query the FAISS index. The system returns K=3 most similar documents based on cosine similarity (dot product of normalized vectors).
- 3.Context Augmentation: Retrieved documents R₁, R₂, R₃ are concatenated: Context = R1 ⊕ R2 ⊕ R3
- 4.LLM Processing: We tokenize both context and target document, then pass Input = C ⊕ Dtok through the LLM (Qwen3-0.6B) to get logits (unnormalized log probabilities).
- 5.Arithmetic Coding: Logits are converted to probabilities via softmax, then arithmetic coding compresses the document tokens. The expected compressed length for token tj is -log2 P(tj | t<j, Context) bits.
Technical Implementation Details
Embedding Model Architecture
We use Qwen3-Embedding-0.6B, a dense embedding model that transforms variable-length text into fixed-size 512-dimensional vectors. The model uses:
- •Transformer architecture with 12 layers, 768 hidden dimensions
- •Mean pooling over token embeddings to get document representation
- •L2 normalization for cosine similarity computation
Arithmetic Coding Process
Arithmetic coding represents a message as an interval [low, high) within [0,1). For each token:
Get probability distribution:
P = softmax(logits)
Partition current interval proportionally:
new_low = low + (high - low) × CDF[t-1]
new_high = low + (high - low) × CDF[t]
Final interval uniquely identifies the sequence
The compressed size is approximately ⌈-log2(high - low)⌉ bits
FAISS Indexing Strategy
We use FAISS with IndexFlatIP (Inner Product) for exact similarity search:
# Build index
index = faiss.IndexFlatIP(embedding_dim)
index.add(normalized_embeddings)
# Query: retrieve top-K
distances, indices = index.search(query_embedding, k=3)For larger knowledge bases (>10K docs), we can use IndexIVFFlat with clustering for approximate search with ~10x speedup.
Information-Theoretic Foundation
Why Better Predictions = Better Compression
The connection between prediction and compression is fundamental in information theory:
Cross-Entropy Loss (used in LLM training):
L = -∑j log Pθ(tj | t<j, Context)
Minimizing this loss = maximizing prediction accuracy = minimizing expected code length
Compression Ratio:
CR = |Original| / |Compressed| = (N × 8) / ∑j(-log2 P(tj))
where N is document length in bytes
Bits Per Byte (BPB) - our primary metric:
BPB = ∑j(-log2 P(tj)) / N
Lower BPB = better compression. Random data: BPB ≈ 8. Good compression: BPB < 2
RAG's Impact on Perplexity
Perplexity measures how "surprised" the model is by the next token:
Perplexity = 2(average -log2 P(tj))
By providing relevant context via RAG, we expect to reduce perplexity by 10-30%, directly translating to proportional compression improvements.
Evaluation Methodology
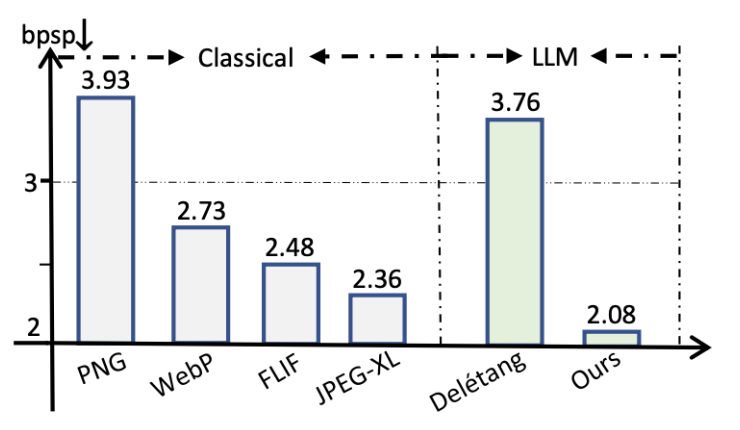
Benchmark Datasets
- •enwik8: First 10⁸ bytes of English Wikipedia (standard compression benchmark)
Used in Large Text Compression Benchmark - •Cosmopedia-100k: 100,000 diverse educational documents
Tests generalization across domains - •Wikipedia 2023 dump: ~5000 articles for knowledge base construction
Completely separate from test set to prevent leakage
Baseline Comparisons
| Method | Type | Purpose |
|---|---|---|
| gzip / bzip2 / LZMA | Traditional | Practical baseline |
| Vanilla LLM (no RAG) | AI-based | Primary comparison |
| RAG-Enhanced LLM | Our method | Novel approach |
Ablation Studies
We systematically vary parameters to understand RAG's contribution:
- →K (retrieval count): Test K = 1, 3, 5, 10 documents
- →Knowledge base size: 1K, 3K, 5K Wikipedia articles
- →Document similarity threshold: Only retrieve if cosine similarity > 0.7
- →Domain specificity: Test on general text vs. technical documents
Success Criteria
- ✓Primary: Statistically significant improvement (p < 0.05) over vanilla LLM on ≥2 datasets
- ✓Secondary: ≥5% better compression ratio than baseline
- ✓Validation: Bit-perfect lossless reconstruction verified
- ✓Stretch: Outperform gzip on text-heavy datasets
Impact and Applications
💰 Economic Impact
Cloud storage costs ~$0.023/GB/month (AWS S3). For enterprises storing petabytes, 5-10% compression improvement = millions in annual savings.
⚡ Network Efficiency
Better compression reduces bandwidth usage. Critical for mobile networks, CDNs, and real-time applications like video streaming.
🌍 Environmental
Data centers consume ~1% of global electricity. Efficient compression → less storage → fewer data centers → reduced carbon footprint.
🚀 Scalability
RAG scales independently: add domain knowledge without retraining models. Adapts to specialized data (medical, legal, code) by swapping knowledge bases.
Research Contribution
This research bridges two powerful paradigms: the predictive capabilities of large language models and the contextual enhancement of retrieval-augmented systems. By addressing the finite context window limitation of LLMs through dynamic knowledge retrieval, we open a new avenue for intelligent compression that combines statistical learning with semantic understanding.
The key innovation lies in treating compression as a prediction problem where better context leads to better predictions, and better predictions mathematically guarantee better compression through the fundamental laws of information theory. This approach is model-agnostic and can be applied to any domain with available reference corpora.
Technical Stack
LLM
Qwen3-0.6B
Embeddings
Qwen3-Embed
Vector DB
FAISS
Coding
Arithmetic